Esta página está en construcción: perdonen los errores y temas inacabados.
This page is being developed: I am sorry for errors and unfinished subjects.
CODIFICATION OF ENGLISH PROSODY
A direct approach to English prosody –understood as intonation and rhythm– is hereby presented. The intonation curve is approximated by a series of straights alternatively ascending and descending. Peaks and valleys mark the essential points in the intonation pattern, since they relate to accents, focus, commas, full stops and other important syntactical and semantic points –instants– in the spoken text.
Index
Abstract
Introduction
Aim
Intonation Curve
Coding
Similarity and distance
Test procedure
Tests
Results
Conclusions
References
Introduction
Usual Coding of Intonation Patterns
Pitch patterns and their Coding
|
|
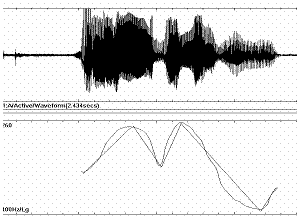
The pattern (Fig.1) is converted into a polygonal composed by alternatively ascending and descending straights, which will called slopes here. The tonal jump will be measured in semitones, a pitch interval used in music with a value of a 6% change, positive when going up and negative otherwise. Pitch never stay constant, except in music; thus we do not need a code for this stable situation in speech.
The tonal heights or pitches will be equally measured in semitones from the reference 100 hz, –which roughly corresponds to a musical G3 (Sol 3).
The conversion formula between intervals measured in frquency ratio and semitones are:
SEM = 12 / log(2) H log(f2/f1) f2 = f1 H exp (SEM H log(2) / 12)
for intervals; and for pitches (where f1=100 hz):
SEM = 12 / log(2) H log(f2/100) f2 = 100 H exp (SEM H log(2) / 12)
The tonal pattern is, therefore, reduced to a vector (unidimentional matrix) of so many coordinates as slopes; their value will be the tonal jumps, measured in (positive or negative) semitones:
|
+5 |
-6 |
+6 |
-9 |
Alternatively: The pitch pattern is a sequence of intervals of opposed sign.
Distance
We take, as a measurement of the dissimilarity between two patterns, the mean of their absolute differences of their corresponding elements:
D(P1, P2) = 1/n H Si | pi - p=i |
when their lengths coincide; when they do not, we will prolong the shorter until it equals the longer, and consider the added cells as filled with zero.
For example, the distance between the previous vector and
|
+4 |
-7 |
+8 |
-9 |
is (1+1+2+0)/4 = 1. It is clear that opposite signs in corresponding elements will provoke great distance values, as well as big differences in them, even being of the same sign.
But the pattern is not complete: the tone movements are not projected freely on the text, they are linked to specific syllables, especially the peaks and valleys, the most relevant intonational points. Thus we need another row for our coded pattern: the one which pairs each slope with its extreme syllables; lets us choose the beginning syllable of the slope to be paired with it. So;
|
he |
llo! |
how |
are you |
|
+5 |
-6 |
+6 |
-9 |
|
he |
llo |
how |
-w are you- |
-ou |
|
+9 |
-7 |
+8 |
-15 |
+4 |
|
3 |
2 |
2 |
5 |
1 |
We have now a coded intonation pattern, where actuals durations are avoided: therefore the actual pattern has suffered a transformation by which its time scope has been equalized, normalized, what is called a >time warping= in signal analysis terminology, a necessary operation when we want to compare different utterances of the same text. In Fig.1 we see the original pattern and its polygonal simplification, for a given speaker; in Fig.2, the corresponding numerical pattern in the second row, linked to specific syllables in the utterance, in the first row.
prosódic Pattern
|
|
But prosody also includes time considerations, usually under the form of rhythm. This concept and feeling is related to periodic returns of expected events, in our case, syllables. Thus we need a way of coding this rhythm too, to complete our formalizations of a prosodic pattern.
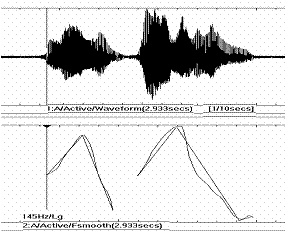
English prosody is rhythmical in an strong part (sic) so it is convenient to include another row to better characterize, prosodically codify, an utterance. This row will be constituted by the durations of each slope. This is the third row in Fig.2. A second utterance of the same text by another speaker (female, almost native), shows the pattern in Fig.3 and the matrix of Fig. 4.
|
he |
llo |
how |
-w are you- |
-ou |
|
+6 |
-12 |
+13 |
-14 |
+1 |
|
2 |
2 |
3 |
3 |
1 |
|
|
Hints for the coding
Some precautions must be taken in order to fill adequately the boxes or cells of the prosódic matrix with numbers that actually represent relevant and actual prosódic parameters. Let us provide some hints for a correct application of our method.
The first problem lays in the pauses, as can be seen comparing Fig.1 and 3: the pause between AHello@ and AHow are you@ shown in Fig.1 is missing in Fig.3; so there is a problem in how to codify both. From the point of view of intonation, pauses are no relevant: they appear anywhere, often without any relation with syntactic facts (against a sad general belief, even of specialists). Thus pauses can be discarded with what both utterances will count the same number of cells.
But there are pauses that cannot be discarded: they are the initial and final ones, always present.
However, even suppressing pauses, the intervals (the >depth= of the valley) will be greater when pauses are uttered: the tone has time to fall and raise again, while, when no pauses are uttered, the tone must raise quickly without reaching the low valley. We will have therefore smaller quantities in the second case, and this for (subjective) similar prosódic behaviour. (look for solutions) One solutions can be isolate, separate each sentence to be measured.
Tasks.
Create a corpus of utterances of a selected number of texts (sentences, groups of them), utter them in Wincecil, print and save the graphs, together with the utterances; codify them, and measure their distances, between speakers of the same native tongue, and between speakers of different tongue. If the first are clearly smaller then the seconds, the codification method is good and can be applied to measure the quality of a foreign speaker. Otherwise the method must be refined.
Vuelta al Principio Última
actualización:
miércoles, 04 de junio de 2014 Visitantes: