Intaxis: a Syntactical Model of Intonation (with J.L.Caramés)
Abstract
In this paper a syntactic intonation model (SIM) is presented. Although intended for present day Spanish, we believe its conclusions and procedures easily generalizable for other languages, once specified their particular tone rules. Since we intended to remain in the syntactical area, we attempted to avoid other contributions to the intonation curve such as pragmatical (mood, modality), morphological, semantic and phonetic information. But all these linguistic levels have shown themselves to be interconnected with each other and with the syntactical level; we have therefore limited –where possible– the generality of our model to neutral assertive sentences with only three syntactical levels: Sentence, Theme–Rheme Syntagma (constituent) and syntagmatic word (SW). Each one of these levels is represented by intonational layers, which, once added up, produce altogether the full sentence intonation. With these boundaries, the model is able to intone automatically a written text, and to provide a foreign speaker with a key to intone a syntactically well ordered (SWO) text. To assess the goodness of this syntactical ordering, the concept is first defined, and then a theorem that states that any syntactical tree can be SWO, is proved. From the SIM a practical punctuation based model (PBM) is derived, using also three punctuation signs: Full Stop, Theme–Rheme Comma and No-Comma (absence of comma). Since syntax is structure in the abstract level, and intonation is structure in the realization level, we will call, reflecting the signifiant/signifié duality, Intaxis this intonational syntaxis. The basic three-level models (SIM and PBM) are afterwards generalized for multi-sentence, multi-level, multi-mood and multi-lingual texts.
Introduction
Spanish intonation has received wide attention but the general approach has been mostly descriptive, as can be seen in Alarcos Llorach (1971), Fernández (1986), Navarro Tomás (1974) and Quilis (1981). The huge complexity of speech intonation seems to have prevented the appearance of simple and systematic models, with the exception of mood prosodemes (asseveration, question and order), which are fairly well typified, perhaps due to their easy perceptibility (see Bergé and Sánchez 1995 for this aspect). Other phenomena, more unconsciously perceived, were overlooked (in the past and even to this day) by scholars who made exclusive usage of their hearing. To this end, measuring devices (when wisely used) have proved to be very useful to detect subtle shades of intonation. We have developed and made extensive use of these tools in this and former studies, as Sánchez (1977, 1979, 1995, 1996) and Bergé and Sánchez (1995).
English intonation, on the other hand, has been well described through definitions, models and notation by Bolinger (1972), O'Connor (1973), Crystal (1975), Lyons (1982), Roelof de Pijper (1983) and Halliday (1988). Besides, more formal approaches have been presented, specially for the syntactical domain, in García Calvo (1979, 1983) –for Spanish–; Pierrehumbert (1981), Selkirk (1984), Kaisse (1985) and (mainly for metrics) Liberman (1975) –for English–; Vaissičre (1974) –for French. Laver (1994) offers a comparative study in several languages in which similar behaviour can de detected, even for tone-languages. All these studies, proceeding from linguists, phoneticians, acousticians and electronic engineers, show the extreme importance of pitch and intonation to separate, construct and express, in speech.
Our initial purpose has been to formalize, until where possible, a SIM, that is, a syntactic intonation model, as well as a synthetic mechanism to intone sentences, adding the contributions of each syntactical level to obtain a global realistic image of natural intonation –the one accepted and understood by the average competent listener. This is useful to understand how syntax is represented by intonation, i.e., how intonation is syntax, and to feed a speech synthesizer with an intonational model in order to read correctly a written text. Let us call Intaxis this tonal structure.
In written text, punctuation constitutes the main source of information on syntactical structure, marking, almost formally, how the lexical chain must be grouped in superior units, until sentence level is reached. But punctuation is vague: commas are arbitrarily used, semicolons do not have a definite status, etc. Moreover, punctuation has a double function, in syntax and mood, as we shall see.
Semantics influences intonation as well. First with the accent or stress, which belongs to the word, more intimately in Spanish, as in 'pal'eto'/'rustic'–'palet'o'/'overcoat', but also to a certain degree in English, as in 'pr'esent'–'pres'ent'. In Spanish, the accent is a phoneme which permits to oppose meaning in phonetically similar chains. Thus the meaningful words, stored in the Lexicon of each language, already influence intonation. Following Garcia Calvo (1979), we call Syntagmatic Word (SW) a meaningful word (as nouns, pronouns, verbs, adjectives, indefinite articles) joined with preceding (proclithic-like) or following (enclithic-like) meaningless word(s) (as definite articles, prepositions, conjunctions, and similar particles), called indices. The SW are basic for our models: they are the lower syntactical units, as we will see. Second, any sentence, since it offers knowledge about the World (Reality), acquires a certain meaningful entity: it becomes a new idea, a new semantic item: phrases as 'Caballo de Troya'/'Troy horse', 'Polvorones de Astorga'/'Astorga sweets', are near to constituting new words. Here syntax semantizes itself.
 This bring us to Morphology. We
see both disciplines as logic (arbitrary) segmentation in a continuous process
of agglutination and fusion, as Figure 1 shows, for the constituent 'Estados
Unidos' / 'United States'. Intonation follows closely this process, with an
absorption of an accent by the other, the previous pair of SW becoming only one
SW, passing through the loss of importance of an accent ( ` ) with respect to
the other ( ' ).
This bring us to Morphology. We
see both disciplines as logic (arbitrary) segmentation in a continuous process
of agglutination and fusion, as Figure 1 shows, for the constituent 'Estados
Unidos' / 'United States'. Intonation follows closely this process, with an
absorption of an accent by the other, the previous pair of SW becoming only one
SW, passing through the loss of importance of an accent ( ` ) with respect to
the other ( ' ).
The assembled pieces may have equal or a different nature: SW-SW ('parabrisas'/'stops+winds', 'correcalles'/ 'run + streets'); index-SW ('Delmonte'/ 'of+the+mount', 'Alcazar'/ 'the+castle'); or index-index ('asimismo'/ 'so+same', 'encima'/ 'in+top'). The accent will usually fall on the second word with equal nature constituents, and on the meaninful word when unequal. Even no accent might be assigned to these new words ('porque'/ 'for+that').
This process can be prolonged upwards, enlarging the strict concept of syntax (i.e., word relations within a sentence) or defining new concepts (text, paragraph, subject, etc.; see the last paragraphs of this paper).
Of course, speech intonation needs a time interval to be uttered and understood. But no special temporal phenomena as syllables, metrics and rhythm seem relevant for intonation and syntax to us: we consider them as related to the act and technique of communication, here included artistic speech, as in poetry and theatre. We treat these matters elsewhere, in Sánchez (1995) and in Sánchez and Puyá (1996); for structured metrics, see Liberman (1975) and Selkirk (1984)
Let us consider Pragmatics (environment, context, empractics, implication, supposition, etc.) as everything that helps the speaker and hearer to find a sense in the sentence as a communication act (Alcaraz Varó 1990; Buhler 1985; Bustos 1986). All the words that point to, as deixis, anaphora and cataphora, belong thus to it. The sentence mood (Downing and Locke 1992) is also included, since, in conversation, the same string of words can be used for different purposes: to ask, to order, to exclaim, to affirm. The theme-rheme question ('theme-proper', in Firbas 1992, quoting Svoboda) is syntactic because of its repercussion on sentence construction but, since this implies a former conversation which constitutes the context of the present one, it is also pragmatic; in the same way as a full stop is as much a sentence conclusion mark as an enonciative sentence indicator, the comma is both a syntagma separator and (often) a theme marker.
Indeed the comma appears performing a great variety of functions, which extends from the optional comma, to that of boundary marker to paratactic sentences, sintagma (group and phrase complexes), etc. We think it useful to begin separating these functions as their intonation contour, in all probability, varies: rising in the pair {Th, Rh} (theme, rheme), and falling in the inverted pair {Rh, Th}, as is usual in Spanish ('/Juán/, se vá\.'/ 'John, is leaving' vs '/Se vá\, Juán\.'/ 'He is leaving, John').
The preceding paragraphs show that, besides pure syntactical intonational elements, we must include in our model other syntax-related linguistic elements.
SpanishSpanish presents great freedom in word order: 'Juan vendrá mańana'/'John will come tomorrow' can be also uttered 'Mańana vendrá Juan', 'Mańana Juan vendrá', 'Juan mańana vendrá', 'Vendrá Juan mańana' and 'Vendrá mańana Juan', despite some slight differences in meaning and style. But this freedom must not break the syntactic coherence of the sentence. To settle this point, let us state a theorem about good word ordering before presenting our model of intonation. We suppose an already parsed sentence, in the usual inverted-tree pattern as shown in Figure 2. The only difference is that we will consider as terminal branches those corresponding to the SW of the sentence, which, as we saw, are the real syntactic words in the sentence –in the figure, branches with two subindices.
TheoremAny tree (partially ordered set) can be SWO at least once.
We consider a tree SWO when:1- It has a good ordering (there is a first element);
2- It has a total ordering (any element has a precedent, except the first);
3- Between any two final branches (SW), there is no other coming from a Common Node higher than their Lower Common Node (LCN):
R121 cannot be between R111 and R112 because the Common Node of the three, R1, is higher than the LCN of the pair.
Let us prove it with an ordering rule, an algorithm: we climb to the first node and place all the SWs belonging to a branch (which so becomes the first, R1) before any SW belonging to the other branches of the same node; we choose another branch as second, R2, and place its SWs before any other SW belonging to the rest of the unused branches of this node. And so on, until all these branches have been used and numbered. R1, R2,.., Rn.
Let us go down to the first node in R1, and let us repeat the previous method, until we obtain the secondary branches R11, R12,..., R1n. We repeat this for all the other branches of similar level, obtaining R21, R22,.., R2n;...; and Rm1, Rm2,.., Rmn. With this algorithm, any SW in a branch (i.e., R22), precedes to any other SW in any other branch with a greater first subindex (i.e., R31)
We continue this process with all the tree nodes until we arrive to the
terminal branches (the SW of the sentence). With that we find that the text
is SWO: any SW precedes (let '>>' symbolize precedes) another
Rijk...lmn >> Ri'j'k'..l'm'
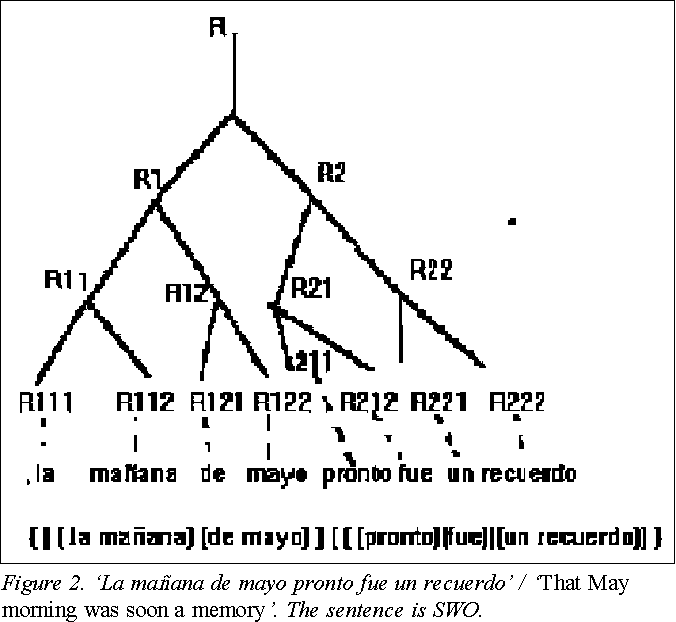
if the first non equal homologue index (it will be k-k', if i=i'; j=j'; k/=k') in both terminal branches is minor for the first SW (k<k'). For instance, R1245 >> R1261, because 4<6. This is also valid for branches of unequal length: R1245 >> R126, should R126 be terminal.
The SWO ordered set (for a binary tree) is, therefore:
R11..11, R11..12, R11..21, R11..22, ..., R12..11, R12..12,..., R21..121, R21..21,...,R22..22
For instance, the lines in an Aleixandre's poem ('La Tierra', Sombra del Paraíso):
".../acaso la corteza pudo un día, / de la tierra, sentirte, humano. .../...
/"... perchance the crust one day, of Earth, did feel you, human ..."
are not SWO because two close SW, 'la corteza' and 'de la tierra' form a hyperbaton, the normal syntactical order being something like:
{humano} {acaso [ (la corteza) (de la tierra)] [(pudo) (sentirte)] [(un día)] ] }.
Therefore, 'humano, acaso la corteza de la tierra pudo sentirte un día' is a SWO sentence, as well as 'acaso un día pudo sentirte la corteza de la tierra, humano.' and some others.
Models
Intonational Grammars
Intonational grammars are those pitch contours that give life, sound to syntactical categories and in turn form a syntax which we believe and this is our proposal, correspond exactly to syntax in the narrow sense. It is a bijective structural relation which binds both and constitutes therefore an isomorphism. The bond is natural if we maintain as other linguists do that syntax is realized through intonation ("l'intonation fait la phrase"). Syntax is intonation, although not all the intonation comes from it, of course. Let us look for the intonation units that mirror syntactic units and will became the elements of our intonational grammars.
The observation of a natural utterance (Figure 3) permits the decomposition of its intonational shape in several syntactically related contributions. In the figure, we see the pitch estimation (F0 contour) for the sentence 'La mamá de Manolo no sabía sumar'/ 'Manolo's mamma did not know how to add up', whose phonetic realization is entirely voiced but for the 's': [lamam'aDeman'olon'osaB'iasum'ar].
In it we can find roughly three syntactic levels, and three corresponding contours can be attached to each level, in such a way that the point-to-point addition of all these curves reproduce the original– as we proceed in the Fourier analysis and synthesis of an analytical function .
The stretches of contours are assembled by inclusion in a similar fashion to that linking syntactic categories; in other SWs sentence contour extends over all phrase constituents and phrase contours over its constituent SW as seen in the figure. In (written) text, starting from punctuation, the sentence curve acts over all the sentence (words between two full stops); the thematic clause curve acts over its words (those between commas or between full stop and comma). The SW curve acts over its words (those between 0's, comma absence), between 0 and comma, and so on: we find a SW between any combination pair of the signs (. ,ş).
The peak of contour level 0, SW, coincides in time with the stress of its corresponding head (lexical) word and the curve shows the tonic prominence of the corresponding syllable and vowel.
These curves have a phonological character, and not merely, a descriptive, although useful, one: a change of punctuation brings a change of intonation and hence a change of sentence meaning and sense; again, "Intonation makes the sentence".
We shall exclude the many varied pragmatic and expressive prosodies that escape for the moment any attempt of coding, (if it is at all possible, because any spoken sentence is also an act, an event). To utter a sentence is to affirm its proposition, should it have no other purpose. We retain, therefore, only those syntactic contours that correspond to sentences uttered without any intention, connotation, context, modality or truth values, without any connection with the real world (we insist, if that is at all possible). As neutral sentence mood we will use the asseverative, using full stops as sentence boundary, commas as syntagma delimiters and comma absence as boundaries between SWs. Only three syntactical levels will thus be considered: Sentence, Syntagm and SW. No quantity and intensity are used.
We limit our model to the spoken Spanish (Castilian), in its educated variety (university, radio and TV), but, as we said before, we believe its validity to extend to other Spanish and Western languages (see the Multi-lingual paragraph)
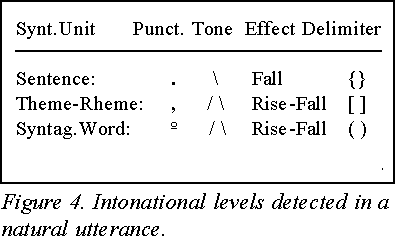
SIM Syntactical Levels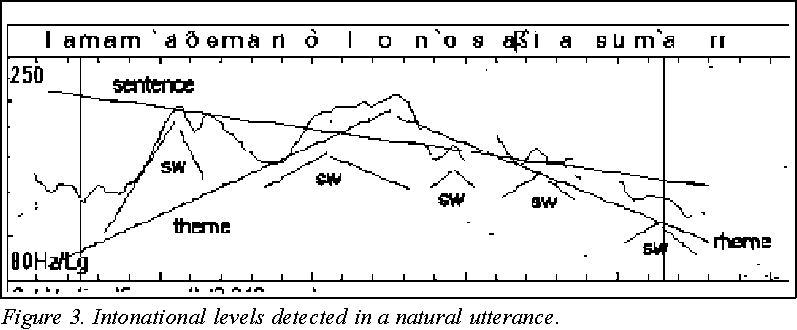
We adopt three basic intactic (syntactic-intonational) levels, as can be seen in Figure 4.
The tonal contribution of all syntactical units are added, point to point: thus a word will receive the contribution of all the units to which it belongs: in a sentence as 'El perro come carne de vaca'/ 'The dog eats cow's meat', the word 'perro' will therefore receive three syntactical contributions: those of the sentence, the theme, and the SW (Figure 5). The higher pitch in the SW coincides with the accent of the SW word-nucleus. Since the sum of several straight lines is a straight, we find always a straight as the tonal variation between one accent and a contiguous punctuation sign, as the lower pitch line of the figure shows; we encounter then:
A PBM: Punctuation Based Model of SIM

From a SWO written text, a Tonal Text (TT) is derived: it is defined as a succession of pairs (a s), preceded by an initial s:
TT = s ( n (a s)) A = {´ Ra} h a S = {ř , .} h s
where means concatenate, n n-multiple concatenation (n, natural number), 'a' is either an Accentuation Rule (Ra) or a graphical sign (') which means (tonal) accentuation; s is any of the normal punctuation signs ( . , ) complemented with an absence sign, ř, omitted in plain writing. Ra are idiomatic (last syllable in French, any in Spanish), and so is the graphical accent, present in Spanish and a few more languages. The intonation of this TT will be made with tonal variations belonging to set I = { / \ } (rising or falling tones). The intonation curve will be: E = 2n i, a succession of tonal intervals, interspersed in the TT chain in the way: [ s i s i s i a i s i a i s ]. For instance, the former sentence: 'El perro come..., with the intonational structure: . /{/[(el_p/'e\rro)]/ \[[(c/'o\me)][(c/'a\rne)(de_v/'a\ca)]]\}\ . gives the TT shown in Figure 6.
Practical Implementation of PBMThe described models have been implemented in the computer to assess their perceptual validity. Any Spanish text (in a computer file or manually entered) is converted into two strings: one phonetical, by means of a set of rules for its alphabetical-phonetical transcription; the other is composed of blanks (no event), accents ( ' ), commas ( , ), full stops ( . ) and no-commas ( ş ).

These punctuation signs have been taken, either from the text itself (commas, full stops, Spanish graphical accents) or derived from a set of rules on Spanish accent (which can fall on any syllable, as is known). The program, SETS32, Sánchez and Becerra (1991), can then concatenate phonetics stretches corresponding to the phonetic string obtained from the text, assigning the whole signal a melody derived from the punctuation string by adding together the tonal contributions of each syntactical level suggested by these punctuation signs, as formalized above.
We have found the absolute and relative degrees of falling and rising curves –straights in our case– very important. Our choices have been: ** -7 semitones (a fifth, 3:2 ratio) between beginning and end of sentence falling curve (compensated with +7 semitones from the sentence end till the beginning of the next one). ** +7 semitones between the theme-rheme comma peak and the extremes (theme beginning and rheme ending). ** +3 semitones in the accent peak of a SW.
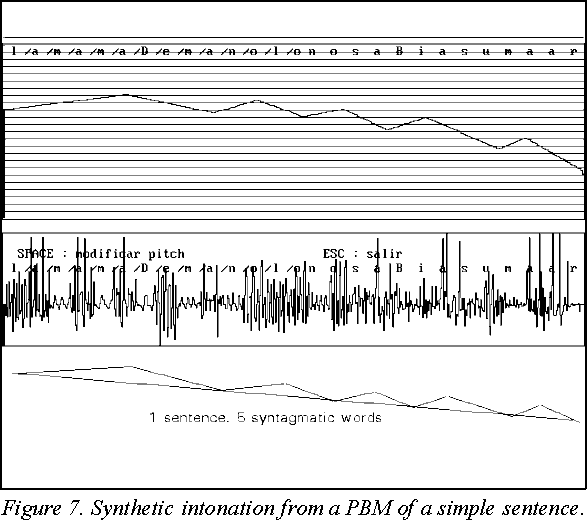
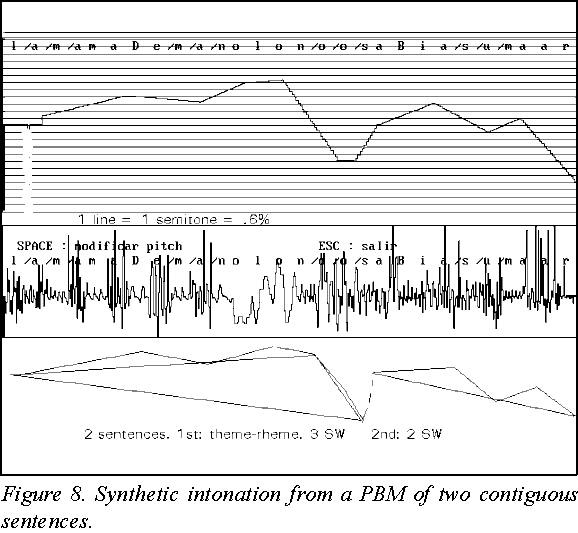
Let us see some melodic contours assigned to the sentence used above: 'La mamá de Manolo no sabía sumar'. They depend on the particular syntactic structure of the sentence(s), which in turn has been derived from the punctuation signs embedded in the text. Two cases are shown in Figure 7 and 8: one sentence without theme-rheme; and a two-sentences utterance, the first with one theme-rheme and the second without (full stop after 'no').
Generalisations of SIM and PBM
Pitch Contour Simplifications
Straight segments have been selected to join low and high points in intonation curves due to the simplicity of conception and computation. But naturally other curves can be selected, probably with a closer approximation to the natural intonation. The main improvements that we foresee are an initial rise in the onset of the sentence curve, and an additional segment in the SW curve for those with 3 or more syllables, in the way: ' \ / \ ', which improves the naturalness by emphasizing the accent place.
Other prosodic traits
In our model, only pitch/tone has been used as the perceptive trait that realizes syntax: indeed it is the most important, and is sufficient to express the finest shades in all the linguistic levels mentioned above. However, other features contribute as well to the naturalness, and therefore to the effectiveness, of the pitch melody.
The main additional trait is quantity, useful in (at least) two ways: the first is the trait itself used as marker or emphasízer: any speech segment becomes prominent when given length: accents, improve thus their perceptibility when lengthened. The second function of quantity is related to pitch: the complex movements need time to be produced and perceived. For instance, neighbor pitch phenomena as stress and full stop only complete their realization by allowing vowel pitch rise and fall according to the prosodic circumstances. Let us take the pair of sentences 'No! Stop!'. At least three stages can be found for each vowel: rise to the accent peak, accent, fall from the accent and/sentence, as the diagram in Figure 9 shows. Pauses, as well as useful separators, are in a way similar to quantity: as void intervals, they take their attributes from the previous events, thus prolonging them.
Intensity enhances syntactical and phonetic situations, as in the accent –stress. This trait is concomitant with pitch, and therefore, the sentence begins with more energy than at the end (indeed, vowels at the end of a final sentence are often unvoiced, as a result of this gradual fading).
Timbre can also be used in accents, making their peak vowels clearer (that is, more distinct from the neutral vowel, schwa) than the unaccented.
Multi-level below the Sentence's
 The simple three-level structure
described previously can be generalized to several syntactic levels, always
between the extremes, S and SW. Each new level will be suggested by an
additional comma, which will mark both the peak intonation and the boundary
between a new theme-rheme construction. These new levels complicate the sentence
by offering many possibilities for their relative positions. Indeed each comma
must be ascribed to one of the levels, the number of different organizations
growing geometrically with the number of levels: the maximum number of
syntactical structures is the number of permutations of the indices that ascribe
each comma to a particular level, Pn = n !, which gives
the pairs (n, Pn): (1,1); (2,3); (3,6), (4,24). To actually find one
of them one must choose the comma with the higher level (below the sentence's);
afterwards one of the remaining commas in each half must be chosen as the
higher, and so in each new division, until all have been ascribed an order. For
this purpose a simple extended punctuation can be used, by repeating the usual
sign so many times as its level order. A text as 'Mi mamá, alegremente,
gastaba mucho. La mamá de Manolo, no, sabía sumar.' /'My mamma, wildly,
spent a lot. Manolo's mamma, no, she knew how to add up.' could thus be
punctuated as '.. Mi mamá , alegremente ,, gastaba mucho . La mamá de
Manolo , no ,, sabía sumar..' where two levels of commas and full stops
have been used, showing a richer syntactic content than that of normal
punctuation.
The simple three-level structure
described previously can be generalized to several syntactic levels, always
between the extremes, S and SW. Each new level will be suggested by an
additional comma, which will mark both the peak intonation and the boundary
between a new theme-rheme construction. These new levels complicate the sentence
by offering many possibilities for their relative positions. Indeed each comma
must be ascribed to one of the levels, the number of different organizations
growing geometrically with the number of levels: the maximum number of
syntactical structures is the number of permutations of the indices that ascribe
each comma to a particular level, Pn = n !, which gives
the pairs (n, Pn): (1,1); (2,3); (3,6), (4,24). To actually find one
of them one must choose the comma with the higher level (below the sentence's);
afterwards one of the remaining commas in each half must be chosen as the
higher, and so in each new division, until all have been ascribed an order. For
this purpose a simple extended punctuation can be used, by repeating the usual
sign so many times as its level order. A text as 'Mi mamá, alegremente,
gastaba mucho. La mamá de Manolo, no, sabía sumar.' /'My mamma, wildly,
spent a lot. Manolo's mamma, no, she knew how to add up.' could thus be
punctuated as '.. Mi mamá , alegremente ,, gastaba mucho . La mamá de
Manolo , no ,, sabía sumar..' where two levels of commas and full stops
have been used, showing a richer syntactic content than that of normal
punctuation.
The implementation of these structures in our SIM will use any previous parsing information on the sentence. But, in absence of that parsing, one canonical order must be selected in our alternative PBM: our choice has been to consider the last as the higher in hierarchy, in the whole sentence and in each part so formed as well. That technique will consider the last portion (text between the last comma and the final full stop) as the rheme of the whole sentence, RH0; the penultimate as the rheme, RH1, of the first theme, TH0, and so on. Corelatively, the first portion will be the first theme RHn of the lower division. Thus we rediscover a punctuation-based syntactical tree.
Multi-sentence level
A higher level than sentence seems to be necessary. The speech equivalent to the written paragraph uses at least two intactical full stops: the intermediate and the final, which are differentiated by using a stronger fall for the last one (with an optional pause). This intactical paragraph is intoned in our model with an additional falling curve (straight in our implementation) that covers all the spoken paragraph. Of course, the longer the paragraph, the slighter the fall (otherwise several octaves would be necessary), and more perceptually difficult is the grasping of this slight fall. But the situation is equally difficult to decode in human speech.
Multi-mood
In the preceding paragraphs, only declarative sentences, coupled with falling pitch contours, were considered. But well-known pitch curves for different moods (questions, imperatives,...) can be used instead, substituting the appropriate contour, while maintaining unaltered the rest of the contributions, according to our layer concept. Some problems, however are expected to arise. One of them is the placing of the turning points of these more complex curves. The easy straight fall of the asseverative sentence becomes bent for other moods, and their turning points have to be placed into the temporal scope of the sentence, which could require a syllabic analysis of the utterance, a task avoided so far in our unextended SIM and PBM.
Multi-lingual
Despite the fact that our SIM has been developed for Castilian Spanish, we believe its validity to expand over other Peninsular languages (Catalan, Basque, Galician) and others in our linguistic and cultural vicinity. Indeed, sentence gradual falling, peaked accents and theme tonal emphasis are constant in these languages, as can easily be perceived by the ear or measured with electronic and/or mechanical devices. Therefore our SIM could be applied to those languages as well, after some language-dependent adjustments –as the degrees of falls and rises for each level, canonical form for each contour, and so on.
Another task should be adapting the freer Spanish order, which we commented in the Word Order paragraphs, to other more restrictive languages, such as English.
Multi-punctuation
Until now, only commas, no-commas and full stops have been used. Indeed they are the fundamental signs, which represent, despite their ambiguity, the main grammatical structural units. Other punctuation signs however can easily be added to our models, SIM and PBM: first, the mood signs (see 4.5) and functions (in pairs for Spanish): 'ż ?' 'ˇ !'. After the pairs '( )' and '– –', parentheses and inserted clauses, marked by a change of pitch register. No less important are the colon (:) with a surprising almost equal intonation to that of the full stop, and the semicolon, with an imprecise status close to a light full stop. With this last we would count up to three conclusive signs: final and intermediate full stops and semicolons. For intonation of these signs, see Sánchez (1996). We already saw the use of multiple comma and full stop, in the Multi-level... paragraph.
Multi-pragmaticalPragmatics, even when mood has been excluded, is so rich and unexpected that no attempt has been made so far in this study to include its contribution. We do not know even if this contribution can be considered also as a layer to be added to the others (as a cover or coat) as we did with the syntactical layers. Immediate work is being carried out into this interesting area, which lacks delimitation in its scope, description and typification of its intonational behaviors, and classifications of its functions.
Conclusions
A syntactical model for intonation, SIM, has been described, showing how each syntactical level adds its own contribution to the global intonation. Although intonation is a wide subject, a practical model of SIM, PBM, has been applied with satisfactory results: our listeners have understood correctly the different meanings of each syntactical tree attributed to the same text (word + punctuation).
The main concept of SIM is the Layer, a pitch (F0) function that covers all the speech segment corresponding to the text included in the syntactical division. SIM constitutes a (syntactically) global approach to sentence intonation, which, despite its difficulties (some of them mentioned above) we consider successful. It brings useful results, as an improved theoretical knowledge of intonation and syntax –Intaxis–, some interesting applications in Foreign Language Learning, in Actors' training, and a tool in Automatic Speech Synthesis.
References
Alarcos Llorach, Emilio. 1971. Fonología Espańola. Madrid: Gredos.
Alcaraz Varó, Enrique. 1990. Tres Paradigmas de la Investigación Lingüística. Alcoy: Marfil.
Bergé, Héliane and Sánchez, F. Javier. 1995. "Percepción tonal consciente e inconsciente en el habla". In Actas Cong. AESLA 95 Castellón: Aesla.
Bolinger, Dwight (ed). 1972. Intonation. London: Penguin.
Buhler, Karl. 1985. Teoría del Lenguaje. Madrid: Alianza.
Bustos, Eduardo. 1986. Pragmática del Espańol. Madrid: UNED.
Crystal, David. 1975. The English tone of voice. London: Arnold.
Downing, Angela and Locke, Philip. 1992. A University Course in English Grammar. London: Prentice Hall.
Fernández Ramírez, Salvador. 1986. Los sonidos in Polo, J. (ed). Gramática Espańola 2. Madrid: Arco.
Firbas, Jan. 1992. Functional sentence perspective in written and spoken communication.Cambridge: Cambridge University Press: 80.
García Calvo, Agustín. 1979. Del Lenguaje. Madrid: Lucina.
García Calvo, Agustín. 1983. De la Construcción ( Del Lenguaje II ). Madrid: Lucina.
Halliday, M.A.K. 1988. An Introduction to Functional Grammar. London: Arnold.
Kaisse, Ellen M. 1985. Connected Speech. The Interaction of Syntax and Phonology. Orlando, Fl: Academic Press.
Laver, John. 1994. Principles of Phonetics. Cambridge: Cambridge University Press.
Liberman, Mark. 1975. The intonational system of English. Ph.D. Thesis. M.I.T. (distributed by Indiana Linguistic Club).
Lyons, John. 1982. Language and Linguistics. Cambridge: Cambridge Univ.Press.
Navarro Tomás, Tomás. 1974. Manual de Entonación Espańola. Madrid: Guadarrama.
O'Connor, J.D. 1973. Phonetics. Harmonsdworth: Penguin.
Pierrehumbert, Janet. 1981. "Synthesizing intonation". JASA. 70(4). Oct.
Quilis, Antonio. 1981. Fonética Acústica de la Lengua Espańola. Madrid: Gredos.
Roelof de Pijper, Jan. 1983. Modelling British Intonation. Dordrecht: Foris / Cinnaminson.
Sánchez, F. Javier. 1977. "Application of Dissimilarity and Aperiodicity Functions to Pitch Extraction and Voiced- Unvoiced Decision". Proc. 9ş ICA Cong. Madrid: ICA.
Sánchez, F. Javier. 1979. Tratamiento Seńales Pseudoperiódicas. Ph.D. Thesis Univ. Pol. Madrid: E.T.S. Ing. Industriales.
Sánchez, F. Javier. 1995. "Teoría preliminar de la sílaba". In C. Martín Vide (ed). Lenguajes Naturales y Lenguajes Formales, XI. Barcelona: Promociones y Publicaciones Universitarias: 569-578.
Sánchez, F. Javier. 1996. "En busca de una interválica musical subyacente en la palabra". Lenguajes Naturales y Lenguajes Formales XII. Martín Vide, C. (ed). Barcelona: Promociones y Publicaciones Universitarias: 539-546.
Sánchez, F. Javier and Becerra, Néstor. 1991. "Síntesis de habla por concatenación alofónica" Memoria Interna. Madrid: Lab. Trat. Palabra y Música, IEC-C.S.I.C.: 2-88.
Sánchez, F. Javier. and Bergé, Heliane. 1993. "Hacia una implementación computacional de una Semántica Multicontextual". Leng. Naturales y Leng. Formales, IX. Barcelona: Promociones y Publicaciones Universitarias.
Sánchez, F. Javier and Puyâ, Mojgân. 1996. "Human and machinal recitation model for accentual (Spanish) and quantitative (Persian) metrics". Proc. ICEMCO 96. Cambridge: Cambridge University Press: 8.1.1-8.1.10.
Selkirk, Elisabeth. 1984. Phonology and Syntax: The Relation between Sound and Structure.Cambridge, Mass.: MIT Press.
Vaissičre, Jacqueline. 1974. "Fréquence Fondamentale des phrases déclaratives en français". Abst. 5émes Journ. d'Etudes du Groupe Comm. Parlée. Orsay: Groupe Communication Parlée.
See also a preliminary version in Spanish, ENTAXIS
Back to Main
Last page update:
miércoles, 05 de junio de 2013 Visitors: